Check out the app here: https://spotimmerse.xyz/
Being addicted to various music genres and being sometimes obsessively driven to figure out the story behind the sound means I end up like the squirrel in my backyard hunting pinecones for hours. This is usually a fragmented experience with spotify providing minimal information on the song/artist/album. As a music aficionado in the post-CD era, there is no substitute for poring over the album artwork of art you love.
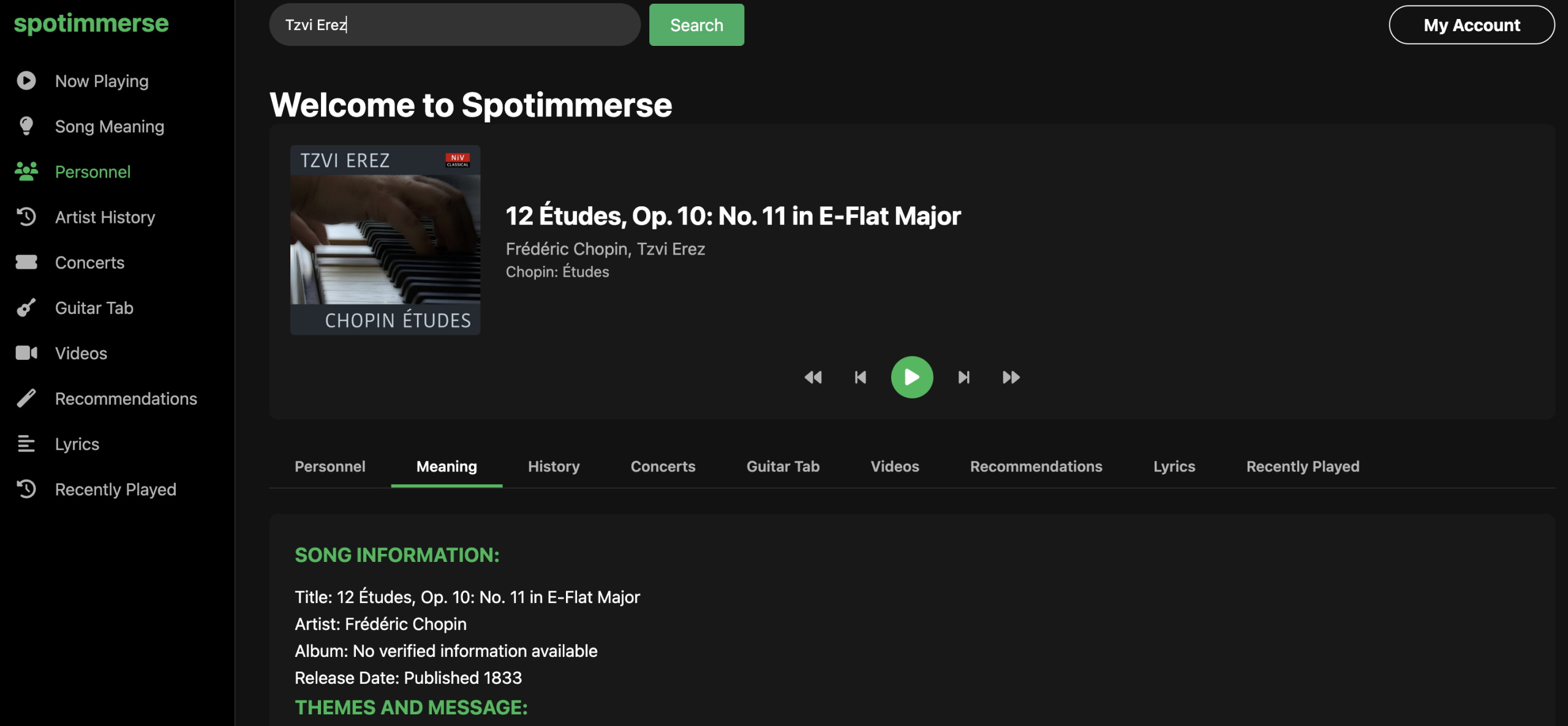
Spotimmerse is the answer to that obsession – get comprehensive information about any song beyond just playing it.
High level architecture
The app is split into two main components with the front end being a vanilla JavaScript single-page application that mimics Spotify’s clean interface and a python flask API backend that orchestrates data from multiple sources
The backend acts as an intelligent data aggregator, making a few AI LLM calls making decisions about which source to use for each type of information. I tried to use a few agentic frameworks to do this but ended up simplifying it by refactoring all the calls myself as that made debugging a lot easier.
Backend:
- Flask API (app.py) with one blueprint (recommendations.py), integrating the below APIs
- Spotify REST API (search, track details, user’s recently played)
- Wikipedia API (content extraction)
- Ticketmaster Discovery API (concerts)
- Google Gemini (analysis, fallbacks)
- Perplexity (guitar tabs generation, this one is a hit or miss usually)
Frontend:
- Static site (index.html, styles.css, app.js) served by serve or any static host
- Vanilla JS controls UI, makes API calls, and integrates Spotify Web Playback SDK
- State: Client-side ephemeral caching in app.js for each tab (lyrics, meaning, personnel, etc.)
- Auth: Server-driven Spotify OAuth code flow, redirecting back with tokens in URL fragment
- Ops: Logging to rotating files, optional console; environment-driven configuration; deployed on Render.com
Data
Rather than relying on a single data source, the app implements what I consider a ‘fallback hierarchy’.
- Primary sources – (Wikipedia, Spotify, Ticketmaster) for factual data
- AI fallback – (Google Gemini) when primary sources fail
- Specialized APIs – (Last.fm, YouTube Music) for specific features
For example, when you request personnel information for a song:
# First, try Wikipedia
search_response = requests.get(WIKI_API_URL, params=search_params)
if not search_data.get("query", {}).get("search"):
# Fall back to Gemini AI
return get_personnel_from_gemini(artist, clean_song)This approach gives you the reliability of curated sources and backs it up with Gemini ( or any other model) when those sources fall short.
AI-assisted meaning, personnel, and history
- For Song Meaning: – based on various models, I ended up using Gemini. The code enforces post-processing to normalize headings and spacing for better rendering on the client.
- Personnel: Prefers Wikipedia sections; falls back to Gemini if missing. Regex-based extraction tries multiple common section names.
- Artist History: Uses Wikipedia intro if available; otherwise Gemini, then extracts sections for display.
Concerts via Ticketmaster
Concert lookup resolves an artist attraction ID then fetches sorted events, formatting only the essentials (date, venue, city, state, country, URL).
YouTube videos via YTMusic
The API prioritizes official music videos and then merges other results, returning embeddable URLs for the client. This was cool and i ended up discovering random videos related to the song on YT.
Responses
As expected, getting the AI responses to be consistent and useful took time with a lot of prompt tuning. I felt like the guy who tunes my kid’s piano every 6 months . To optimize cost, I used the Gemini 2.5 Flash model ( thanks Google!), but the key insight was to keep tuning the prompts to minimize gibberish.
Instead of generic prompts, I created highly structured templates for each content type:
def get_song_meaning_prompt(song, artist):
return f"""Provide factual information about "{song}" by {artist} using this exact structure:
SONG INFORMATION:
Title: {song}
Artist: {artist}
Album: [Album name]
Release Date: [Date]
THEMES AND MESSAGE:
[Describe main themes/message in 2-3 paragraphs. Be insightful but factual.]
INSPIRATION:
[Documented inspiration sources and artist quotes if available]
...
"""This was to force the formatting and consistency so that the AI does not start hallucinating like the guy talking to coconuts in that Tom Hanks movie.
Overall approach
This project was a fun pair-programming mix of vibecoding and fixing large swathes of the code to preference – a combo I call “guide” coding. Key ideas were:
- Ensuring a small surface area with a handful of files, minimal abstractions
- Ensuring each external integration has a dedicated endpoint and a predictable JSON contract.
- Graceful fallbacks – so If Wikipedia lacks content, Gemini fills in. If YTMusic lacks official markers, the title heuristic helps.
- Free APIs
Future-friendly improvements
- UI overhaul – make this look like flipping the pages of a booklet
- Central request session with retries and timeouts across all outbound calls.
- Observability and latency logs
- Caching – Small TTL in-memory caches for Wikipedia/Ticketmaster/Gemini to reduce cost and latency
- Open source the code after cleanup
Final thoughts
All in all, there is no substitute for the smell of the mix of fresh plastic and the scent of the paper booklet inside the jewel case. Spotimmerse is yet another poor digital substitute for that nostalgia.