Comfortably numb (from deploying too many agents)
Step one of the 12 steps is admitting you have a problem. So here goes:…

Step one of the 12 steps is admitting you have a problem. So here goes:…
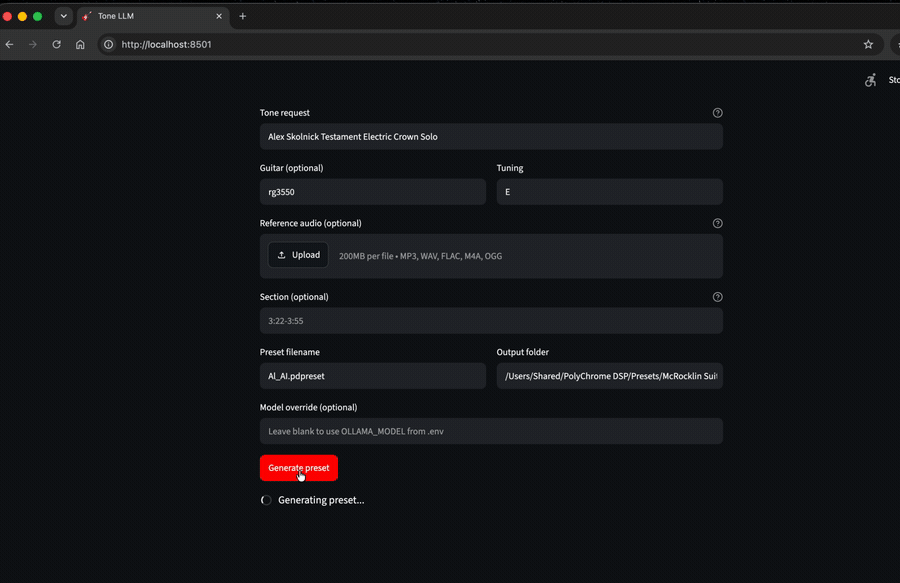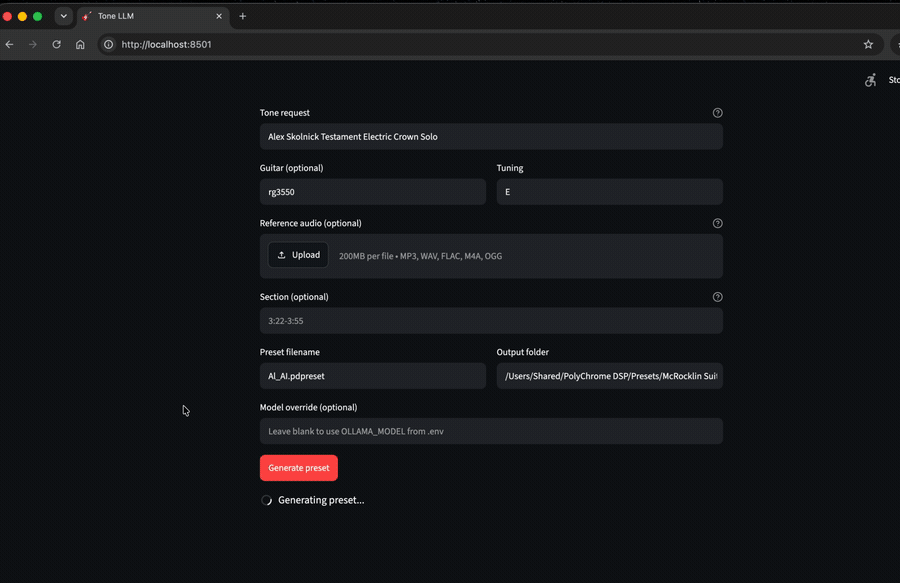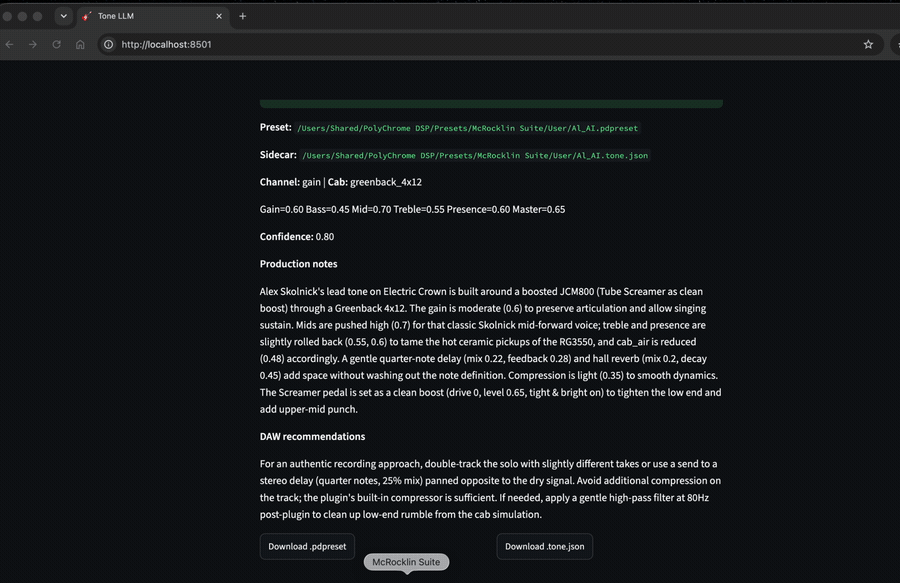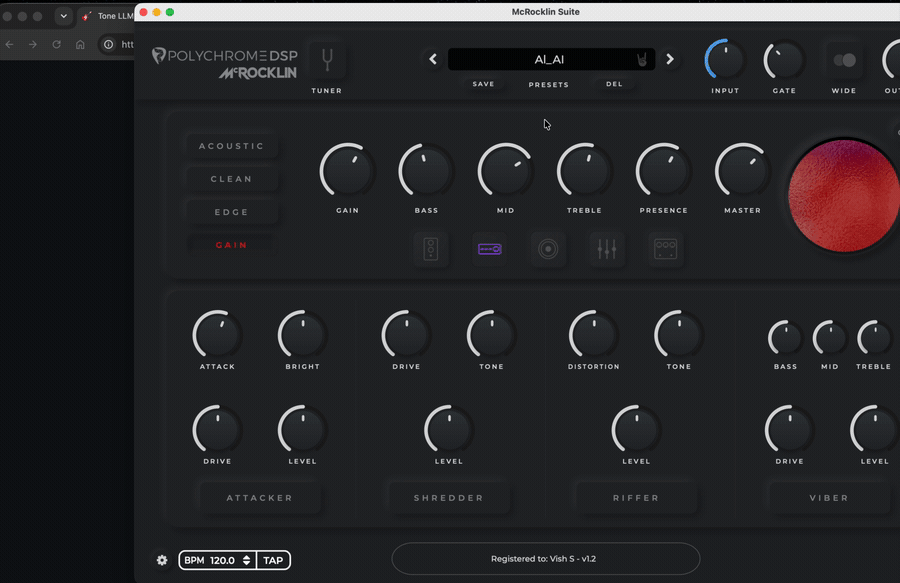
I built tonellm — a Python tool that turns text descriptions into Polychrome DSP amp…

Chrome extension here Chess has always been an intermittent interest of mine even though game…

The Samsung frame TV has a brilliant Art Mode, that I really enjoy, that adds…

Playing around with the Chat GPT, Bard user interfaces has been fun but I end…

I discovered Tenacity while encountering a bunch of gobbledygook shell and python scripts crunched together…

by Sebastian Raschka & Vahid Mirjalili I primarily wanted to read this book due to…
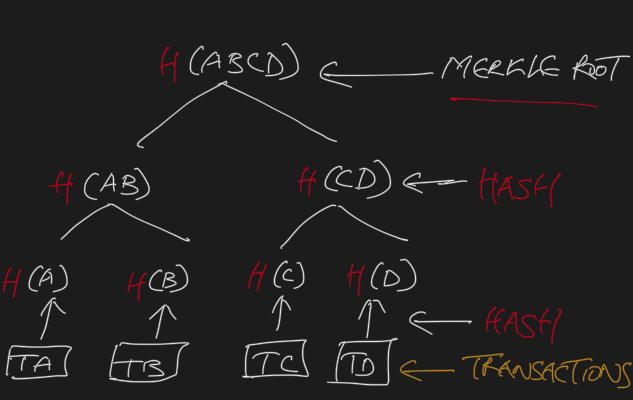
A hash-based comparison approach like Merkle tree would help quickly compare two copies of a…