Do Androids Dream of Vibe Coding?
Flashing CyanogenMod nightlies in 2009 taught me that understanding the build was never the thing…

Flashing CyanogenMod nightlies in 2009 taught me that understanding the build was never the thing…

You can't prompt Suno AI into behaving the way you want, but you can prompt…

A snapshot of my personal AI dev setup as of mid-2026: Hermes for coordination, Cursor…

Step one of the 12 steps is admitting you have a problem. So here goes:…
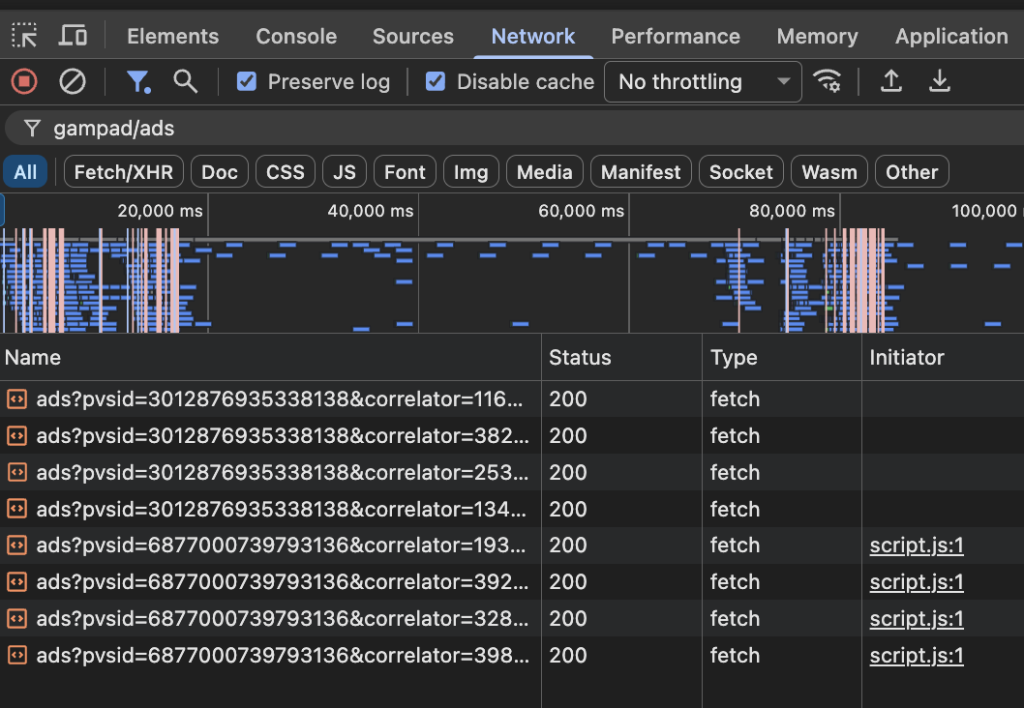
Right now, the reason you got an ad is actually sitting in plain text in…
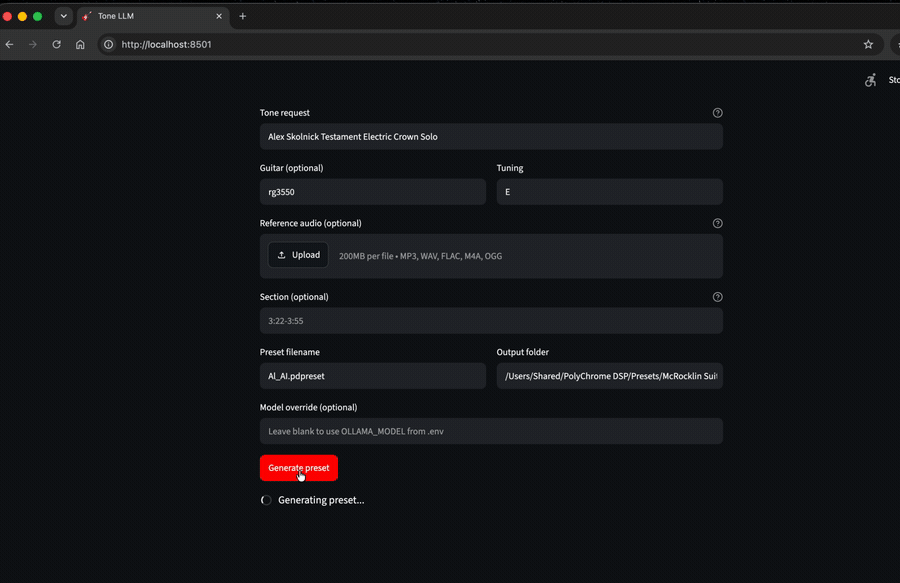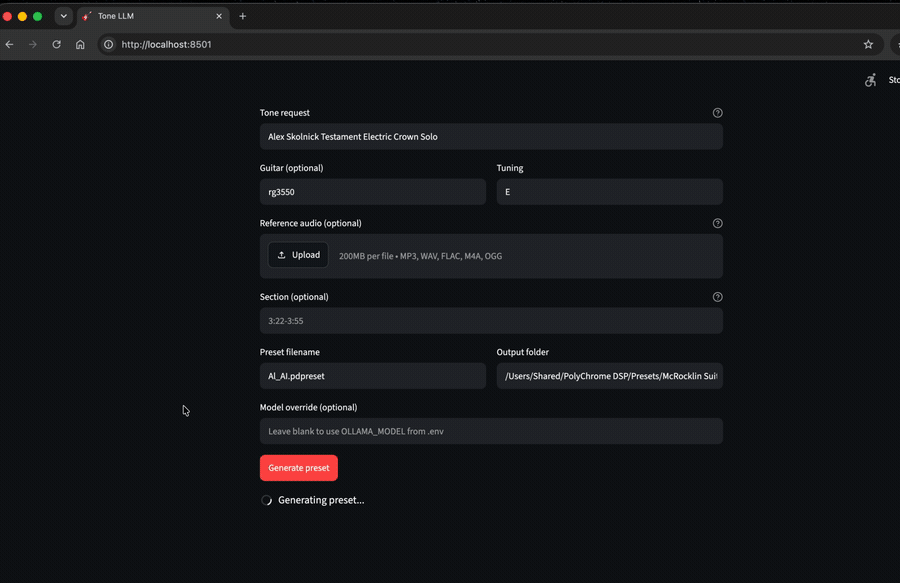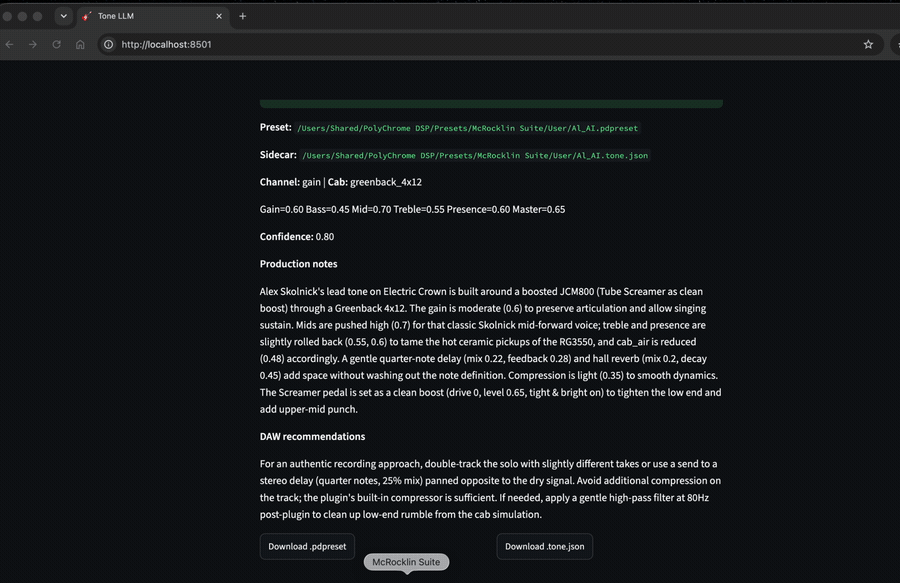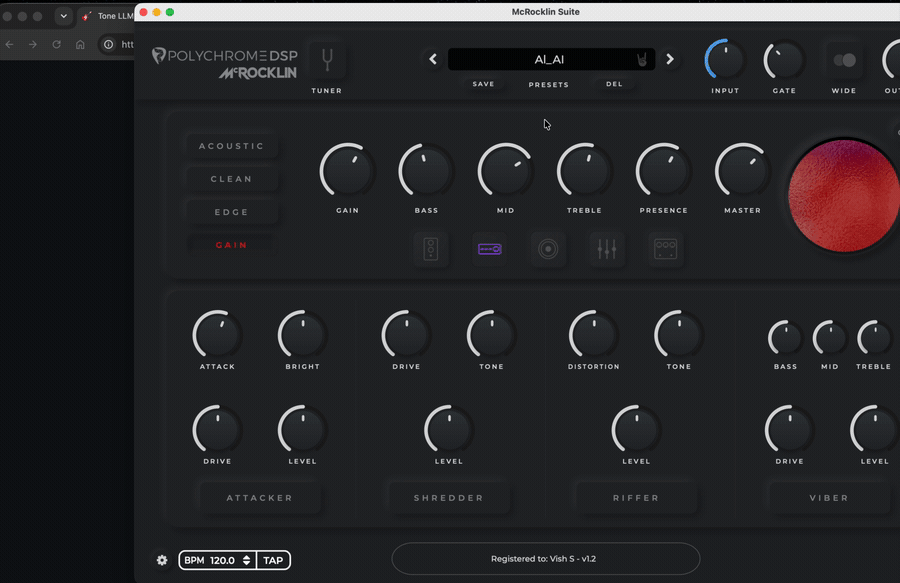
I built tonellm — a Python tool that turns text descriptions into Polychrome DSP amp…

The third-party cookie isn't dead. It's just opt-in now. Which means it's basically dead (like…
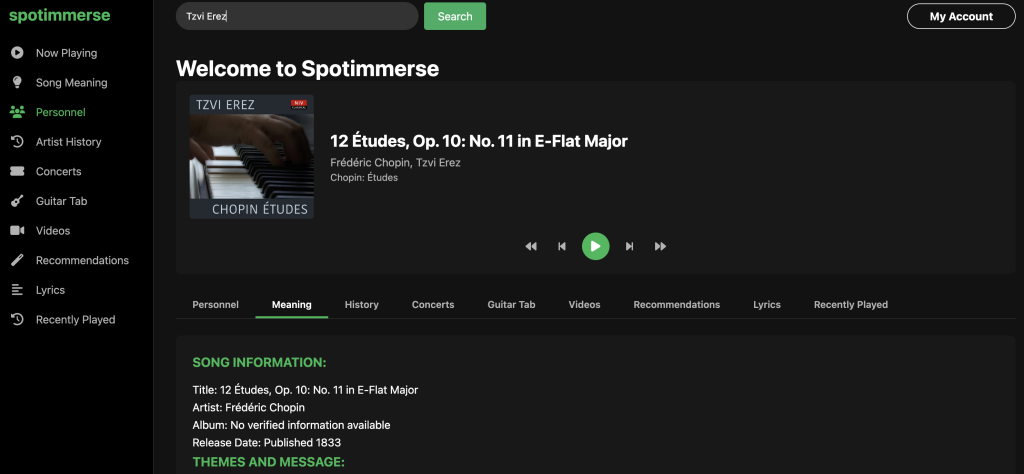
Check out the app here: https://spotimmerse.xyz/ Being addicted to various music genres and being sometimes…
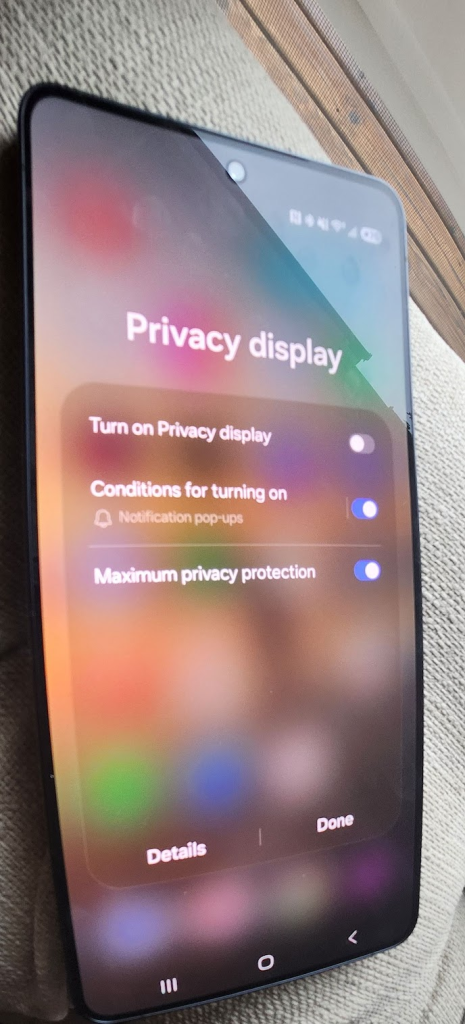
The privacy feature is a major flex on the S26 Ultra.

Data teams need to be able to set up data pipelines that are as fast…