If you think AI near music is heresy and LLMs shouldn’t touch tone — bounce now 🙂
I thought I knew my effects pedal until LLMs came along . The models know every pedal ever made and the conventional wisdom about where each archetype lives in the chain and more importantly, know the exceptions like fuzz before wah for Hendrix tones or compression after reverb for shoegaze bands. Its been humbling pitting my limited pre-existing tones on amp sims versus the settings an LLM can spit out which sound devastatingly better. Though putzing around on a tube amp towering over an effects pedal for 30 minutes to get your sound has its own charm.
If you prefer just looking at the code : tonellm
175B Parameters on your pedal
I’ve been on a late-80s / early-90s tone binge for a while — Amp Sims, Rockman X100 experiments, Dave Williams-style pop rhythm, the usual rabbit holes I wrote about in Unlocking the Groove. Turning knobs by hand is fun until you want “David Williams 80s pop rhythm, chorus and plate” or “Brian May Queen One Vision rhythm” at 11 pm and your brain is fried after a long day of Office Space-ish meetings.
Polychrome DSP ( while i have no affiliation to Polychrome, I recommend this amp simulator that has unlocked so many tones for me!) has become my playground for actually playing those ideas instead of wasting time turning knobs to hone in on the sound.
So I built Tone LLM (tonellm): a small Python tool that turns a text description (and optionally a reference MP3) into a .pdpreset you can load in Polychrome. The trick is not “ask the model to write plugin XML.” The model fills a small JSON contract; Python owns the XML. That split is the whole story — for obsessed axemen who care about why a preset is shaped a certain way, and for AI engineers who care about not shipping hallucinated attributes into a proprietary file format.
Also, its easier arguing with a JSON file than banging your head (headbanging?) against the wall wondering why your tone sounds nothing like the original.
The problem with “just use ChatGPT for presets”
Polychrome presets are XML. Hundreds of attributes, channel-specific prefixes (AC, CA, CB, GA), cab IR slot integers, sync-locked delay subdivisions. LLMs are excellent at sounding like they know an amp; they are unreliable at emitting exact plugin state. One wrong attribute name and the preset is corrupt or silently wrong. Its like stepping on the telecaster clean tone patch while playing a Bathory setlist.
I also didn’t want a second brain for audio. If librosa measures brightness and I also train a classifier for “Marshall vs 5150,” I’d be maintaining two sources of truth. The design goal: one tone engineer (the system prompt) that already speaks in mids, plate verb, and era — optionally flavored by measured features from a reference track so I can laze my way out of what took me hours of research earlier.
Architecture

Inputs
Here’s how the inputs map to intent:
| Input | Required | Role |
|---|---|---|
| Text query | Yes | Artist, song, part, or era — e.g. Phil Collen Run Riot rhythm or Dave Williams 80s pop rhythm |
| Guitar / tuning | No | Compensates pickup output (RG3550 vs Strat, Drop D vs E) |
| Reference audio | No | MP3/WAV/FLAC → spectral features |
| Section | No | Time range on a full mix — isolate the solo |
Outputs
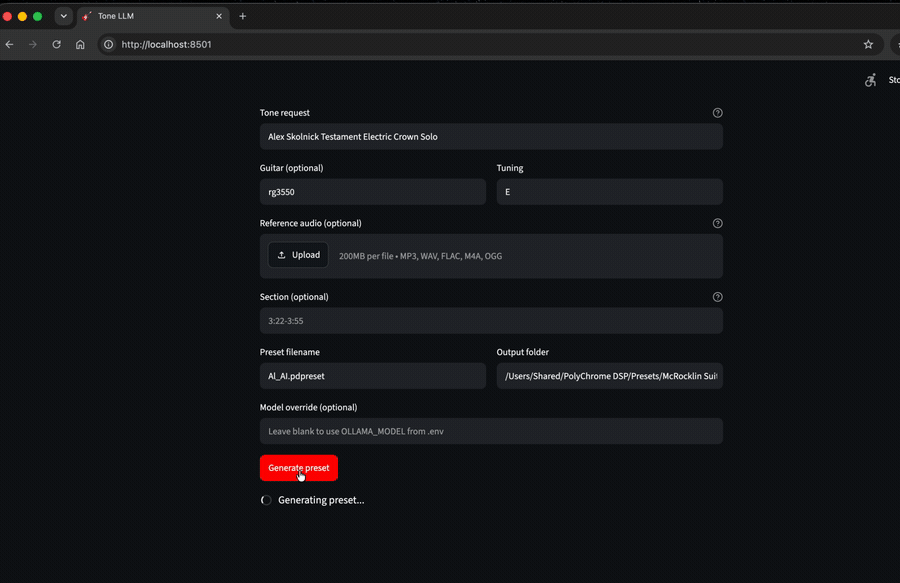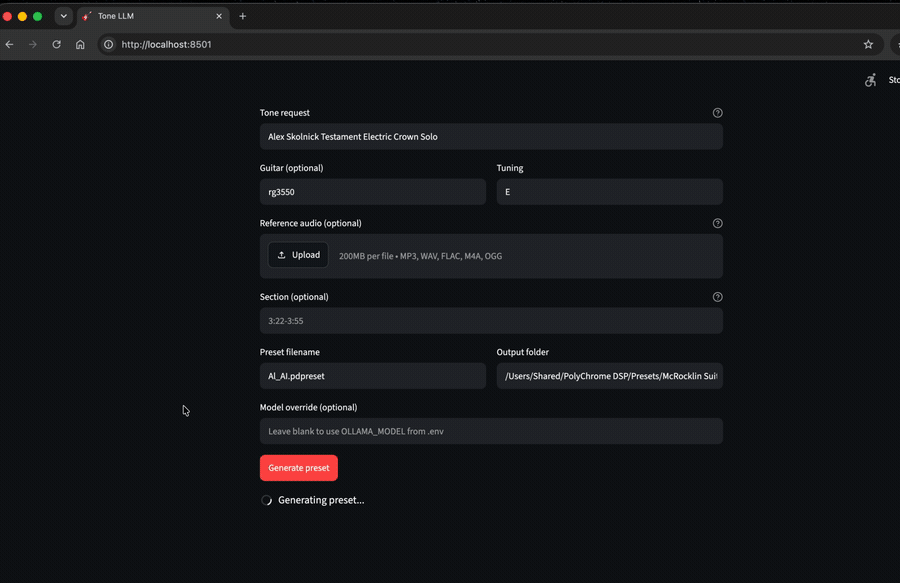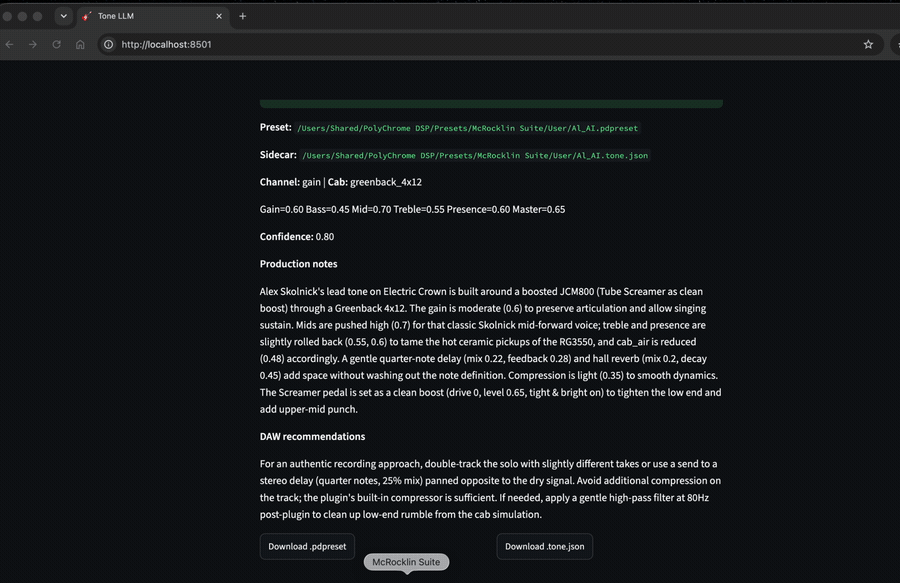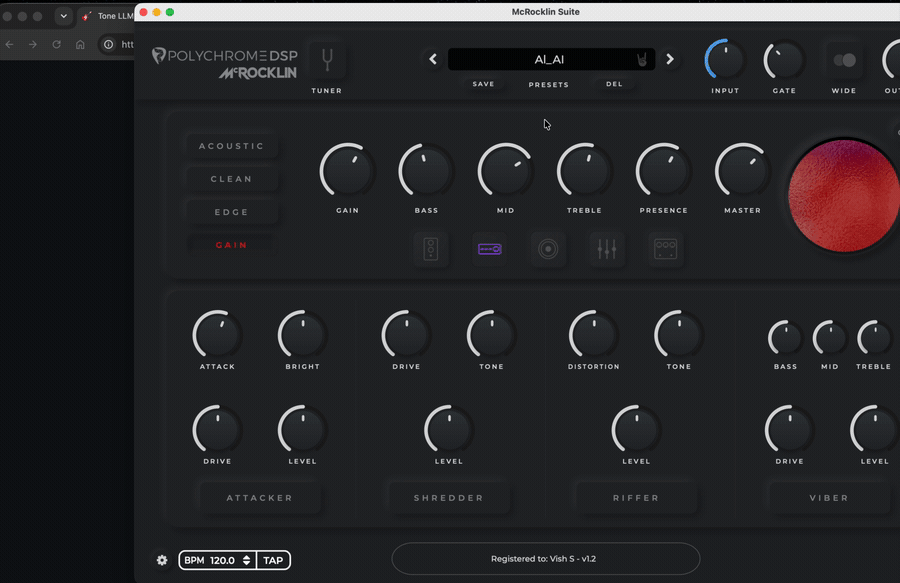
.pdpreset— load in Polychrome User folder.tone.json— same basename, audit and edit without calling the LLM again
Layer 1: The contract (ToneDescriptor)
The LLM never writes plugin XML. It produces a Pydantic model — normalized knobs 0.0–1.0, enums for cab/boost/delay/reverb, plus fields meant for humans:
"""ToneDescriptor: high-level tonal intent emitted by the LLM.
The LLM never writes plugin XML directly. It produces this object,
and a deterministic translator maps it to .pdpreset attributes.
This isolates LLM weirdness from plugin correctness.
"""confidenceis the model’s honest self-ratingproduction_notesis where the pedagogy lives — why these mids, what to listen for, common mistakes for that era.daw_recommendationsis only for what the plugin cannot do (double-tracking, bus comp, post-EQ). The system prompt explicitly forbids telling you to add delay in the DAW when Polychrome already has delay in the descriptor. I kept this on initially and had a few bad outputs when the system kept stacking effects over each other.
Example sidecar fragment (from the repo’s Phil Collen worked example in tone_system.md – your runs will differ and check the video in the README for the results of the lead tone):
{
"artist": "Def Leppard",
"song": "Run Riot",
"era": "1987 Hysteria",
"role": "rhythm",
"amp_channel": "gain",
"gain_amount": 0.62,
"mid": 0.62,
"cab_archetype": "greenback_4x12",
"boost_pedal": "screamer",
"chorus_amount": 0.28,
"delay_role": "off",
"reverb_type": "plate",
"reverb_mix": 0.11,
"widener_on": false,
"confidence": 0.78,
"production_notes": "JCM800 + Rockman X100 layered. Mids forward, NOT scooped. Subtle plate verb and constant chorus give the Rockman sheen."
}Edit mid or chorus_amount, re-run translation — no second API bill:
tonellm from-descriptor RunRiot.tone.json \
-out "/Users/Shared/PolyChrome DSP/Presets/McRocklin Suite/User/RunRiot_v2.pdpreset"That loop is how I actually use the tool: generate, read the sidecar, tweak one or two fields, re-translate.
Layer 2: Where the “tone engineer” lives
I can’t call Mutt to help me patch this tone, this is the next best thing. Domain knowledge lives in prompts/tone_system.md — loaded as the LLM system prompt. Not fine-tuning; prompt as curriculum. A few rules that matter for 80s rock readers (full file in the repo):
Era cheat sheet (abridged)
The system prompt carries this era cheat sheet:
| Era / style | Amp vibe | Cab | Notes |
|---|---|---|---|
| 80s hair / arena (Hysteria, Pyromania) | JCM800 + Rockman layering | greenback / G12-65 | Mids forward, NOT scooped, compressed, subtle chorus, plate verb |
| 80s thrash (MoP era) | Marshall + boost | greenback | Tight, mid-forward |
| Modern djent / prog | High-gain modern | V30 | Tight low-cut, present mids |
Myths the model is told to avoid
- “Heavy = scooped mids” — false for most pre-1995 rock and much modern prog. Default mid 0.5–0.65.
- “More gain = more aggressive” — past ~0.7 gain often mushes pick attack; prefer 0.55–0.7 plus a screamer boost when appropriate.
- “Wide stereo widener on rhythm” — default off; double-track in the DAW.
Guitar compensations — hot ceramic (RG3550): slightly reduce cab air, increase cab_low_cut. Active EMGs: pull gain back a touch. Drop tunings: tighten low end in the cab filters.
This is the same head space as my Power Windows experiments (chorus stacks, Alex-era ambience) and the Rockman clarity obsession in Unlocking the Groove — except now it’s encoded so the model doesn’t “scooped mids” every high-gain request by reflex.
Layer 3: Measuring the recording
Optional -ref runs librosa on the first ~30 seconds (or a -section window). We compute interpretable features — not “this is a Recto”:
- Spectral centroid / rolloff → brightness
- Spectral flatness → tonal vs noise-like (distortion pushes it up)
- Crest factor → squashed vs dynamic
- Band energy (60–250, 250–2k, 2–8 kHz)
- Tempo estimate
Those become natural language appended to the user prompt:
def summarize_for_llm(f: AudioFeatures, section_label: str | None = None) -> str:
"""Human-readable feature summary to inject into the LLM user prompt."""
# ...
"Ground the descriptor in these measurements: match brightness, "
"gain character, and band balance you see in the numbers. "
"If the source is a full mix (drums/bass/vocals present), down-weight "
"low-band energy and crest factor when inferring the guitar's character."On a full mix, solo isolation matters:
tonellm tone "Dave Williams 80s pop rhythm, chorus and plate" \
-guitar rg3550 -tuning E \
-ref ./reference.mp3 -section 0:45-1:15 \
-out ".../Williams_pop_rhythm.pdpreset"(If you do not know Dave Williams by name: he is the session guitarist behind a lot of 80s/90s pop — tight rhythm, clean-plus-chorus, tasteful plate. I chased that feel in Unlocking the Groove.)
Audio flavors the descriptor; it does not replace the text query. Era, style, and player identity still come from your words (who would have thought “crappy tone” had such implications ) – the numbers nudge EQ and gain character toward what you actually hear.
Layer 4: LLM step
This section is the software heart of tonellm. Even if you never touch guitar code, the pattern applies anywhere an LLM must produce machine-readable config for a system you do not control (plugin XML, Terraform, CI YAML, game engine presets).
Not an agent — one deliberate call
I tried experimenting with tool loops and patterns that involved “let me browse the preset folder,” and even tried a multi-step ReAct chain. But it got a bit muddy and overcomplicated for minimal gains.
In the end I settled on a single client.chat() that returns one JSON object. That is intentional:
- Predictable cost — one token bill per preset.
- Predictable failure — either JSON validates or it does not; no partial agent state.
- Predictable debugging — you can log system prompt, user prompt, and raw response.

In with the anti-pattern :
| Approach | What happens | Why it breaks |
|---|---|---|
| LLM writes XML directly | Model emits .pdpreset bytes | Wrong attribute names, invalid floats, no audit trail |
| Agent with tools | Model calls “set_gain(7)” repeatedly | Hard to reproduce, harder to test, easy to drift |
| Schema + translator (this project) | Model fills ToneDescriptor; Python writes XML | Model creativity bounded; XML always structurally valid |
System prompt vs user prompt
System message (tone_system.md): the curriculum. Era → amp/cab table, tone myths, guitar compensations, hard rules (widener off by default, do not punt delay to the DAW). This file changes rarely — I consider this the encoded expertise you will need to embed.
User message (_build_user_prompt): the task. Tone request string, optional guitar/tuning, optional audio paragraph from librosa. This changes every run. I tested against a string of LLMs I had access to and deepseek-v4-pro seemed to give me the closest results. I have more experiments to close out here and hopefully can publish some benchmarking.
parts = [f"Tone request: {query}"]
if guitar:
parts.append(f"Guitar: {guitar} (apply guitar-specific compensations)")
if tuning:
parts.append(f"Tuning: {tuning}")
if audio_summary:
parts.append(audio_summary) # measured features, not a second model
parts.append(
"Produce a ToneDescriptor JSON for McRocklin Polychrome DSP. "
"Set widener_on=false unless explicitly needed. "
"Disable boost/distortion pedals not required for this tone."
)Why not put audio features in the system prompt? Per-request facts belong in the user message. The system prompt stays stable (and on some hosts, easier to treat as reusable context). Same reason you would not put “user_id=420” in a global system instruction.
Grounding without RAG
Grounding here means giving the model evidence it did not invent. tonellm does not use a vector database or retrieval over preset files.
- When you pass
-ref, librosa computes features andsummarize_for_llm()appends a short paragraph to the user prompt: tempo, crest factor, spectral centroid, band energies, plus explicit guidance to down-weight drums on full mixes. - That is prompt grounding: facts in natural language, one reasoning pass. The module docstring states the design choice plainly: measure, don’t classify — no second model that “detects Dual rectifier vs 5150,” which would fight
tone_system.mdfor authority.
When would you add RAG? This is a valid question and I was pretty tempted to add it to bolster my RAG experience. I’ve been bouncing around so many plugins that If I had hundreds of verified artist rig notes, IR metadata sheets, or a preset library with tags that numbered in the 100s, it would make sense to do it. Currently, that’s not the case though I assume as my usage of tonellm scales, it would mandate a RAG at some point.
tonellm is small enough that the system prompt + optional audio stats is enough.
Structured output: four layers of defense
I asked DeepSeek to suggest a few architectures and a TypeScript at the API boundary and Python on the build server pattern seemed light with less overhead.
| Layer | Mechanism | What it catches |
|---|---|---|
| 1 | Ollama format=ToneDescriptor.model_json_schema() | Wrong types, missing fields at generation time |
| 2 | _extract_json() | Markdown fences, prose before/after JSON |
| 3 | ToneDescriptor.model_validate_json() | Enum typos (amp_type vs amp_channel), out-of-range floats |
| 4 | polychrome.py | Assumes valid descriptor; maps to XML deterministically |
Implementation
response = client.chat(
model=model,
messages=[
{"role": "system", "content": _load_system_prompt()},
{"role": "user", "content": _build_user_prompt(query, guitar, tuning, audio_summary)},
],
format=ToneDescriptor.model_json_schema(),
options={"temperature": 0.4},
)
raw = response["message"]["content"]
extracted = _extract_json(raw)
return ToneDescriptor.model_validate_json(extracted)Temperature 0.4 — low enough that repeated runs for the same query are similar; high enough the model can still choose between plausible era interpretations. The “creativity” budget is in the system prompt (era table, production_notes), not in random sampling.
Layer 1 (format=) is not magic. Hosted models still wrap JSON in ```json fences.
On validation failure, the raised error includes the first 1000 characters of raw JSON — so prompt iteration is empirical, not guesswork.
The contract / adapter pattern
ToneDescriptoris the contract: vendor-neutral intent (gain 0.62, greenback cab, quarter delay).polychrome.pyis the adapter: Polychrome-specific XML attribute names and cab slot integers.
Benefits you can reuse elsewhere:
- Swap LLM vendor (Ollama Cloud today, local model tomorrow or opus etc.) without touching XML.
- Swap output target (new translator for Neural DSP, Helix, etc.) without retraining the model.
- Test the adapter with hand-written JSON — no API key required.
The .tone.json sidecar is the human-editable layer of the contract. The LLM is a proposal generator; you are the approver.
Failure modes (and what they teach)
| Symptom | Likely cause | Fix |
|---|---|---|
Pydantic error on amp_type | Model used synonym not in schema | Tighten tone_system.md “exact field names” list |
| JSON inside fences only | Normal for hosted models | _extract_json already handles it |
| Tone sounds wrong but validates | Reasoning error, not syntax error | Edit sidecar; read production_notes and confidence |
| Reference audio misleads EQ | Full mix, no -section | Isolate solo; trust text query for identity |
confidence and production_notes are not fluff — they are UX for judgment. Low confidence 0.85~ means documented-gear territory. That is how you learn to trust the pipeline without treating every preset as gospel.
Recipe: LLM → proprietary config (general)
- Define a small schema — only fields your downstream code can apply (enums + normalized floats).
- Put domain rules in the system prompt — what the model must never do, era tables, myths.
- Put variable evidence in the user prompt — user request, optional measurements, no RAG unless you need it.
- Generate with schema constraint + validate in your language + emit via deterministic codegen — plus an editable artifact (sidecar) for iteration without another LLM call.
tonellm is step 4 with guitar knobs. The same four steps work for infrastructure, game balance, or ad-tech segment configs — the adapter changes, the architecture does not.
Layer 5: Deterministic translator
polychrome.py loads templates/base.pdpreset and patches only what the descriptor implies. Unmentioned attributes inherit from the template — forward-compatible when Polychrome adds knobs.
Cab archetypes map to internal IR slot integers (starting guesses you refine by ear):
CAB_SLOT_MAP: dict[CabArchetype, int] = {
CabArchetype.v30_4x12: 4,
CabArchetype.greenback_4x12: 1,
CabArchetype.g12_65_4x12: 2,
# ...
}Amp channel selects both AmpSel and the knob prefix (GA for gain, CA for clean, etc.). Delay “roles” (quarter, dotted_eighth, ambient) map to sync subdivision positions — best-guess until you audition the sync knob in the UI.
This layer is identical whether the descriptor came from the LLM, your hand-edited sidecar, or some future non-LLM source. Swap the model or the plugin; keep the contract.
How I run it
Web UI (Streamlit, local):
pip install -e ".[ui]"
tonellm ui
# http://localhost:8501 — tone request, optional ref upload, section range, download preset + sidecar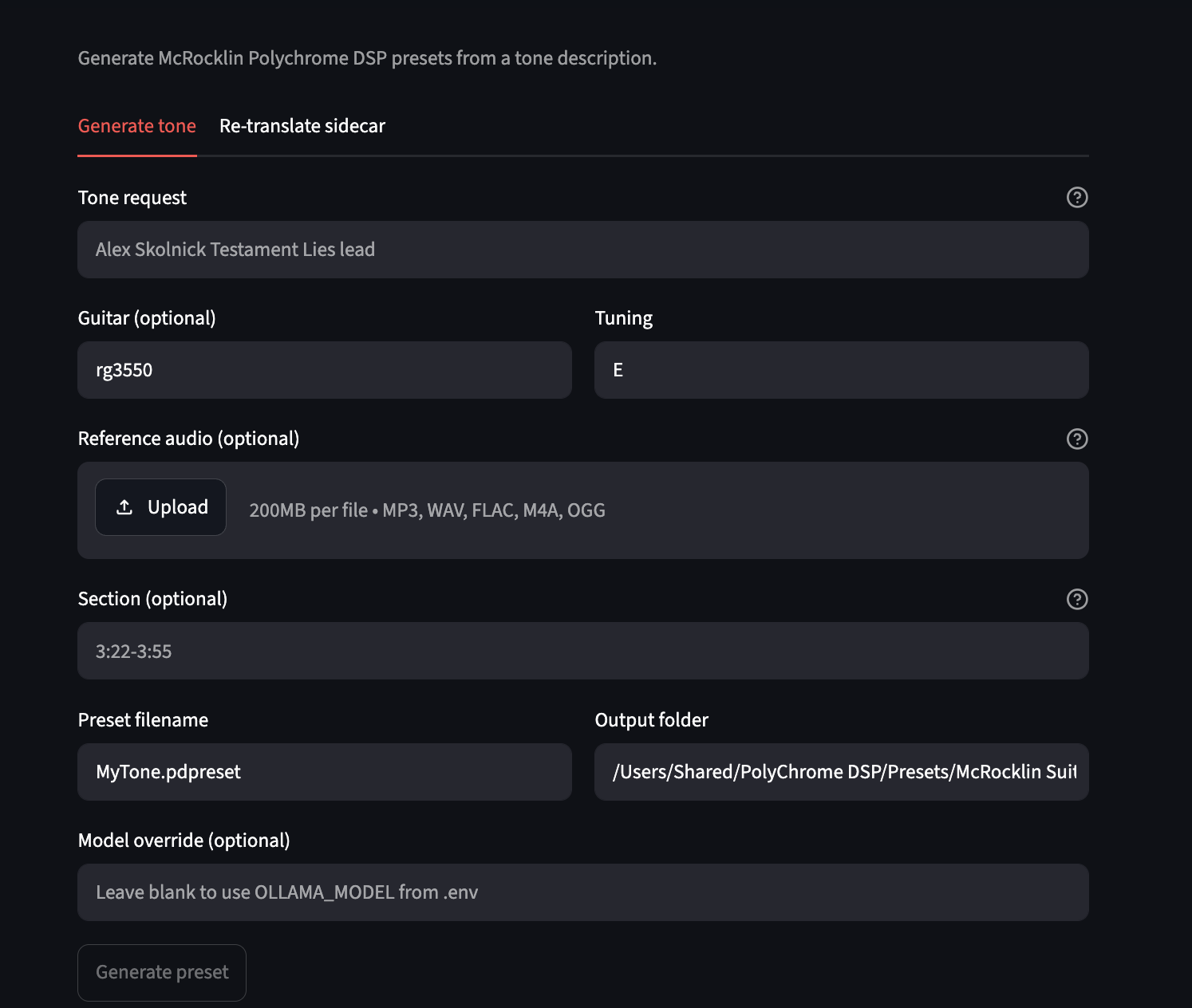
CLI — text only:
tonellm tone "Phil Collen Run Riot rhythm" \
-guitar rg3550 -tuning E \
-out "/Users/Shared/PolyChrome DSP/Presets/McRocklin Suite/User/RunRiot.pdpreset"Env (.env in project root):
OLLAMA_API_KEY=your_key_here
OLLAMA_HOST=https://ollama.com
OLLAMA_MODEL=kimi2.6CLI and UI both call run_tone() in service.py — one pipeline, two interfaces. No duplicate logic to drift.
Honest limits
- Full mixes lie. Low-band energy and crest factor include drums and bass unless you
-sectiona solo. - Cab slots are calibrated by ear. The map in code is a starting point; Polychrome’s IR numbering is the ground truth.
- Presets are starting points, not forensic clones.
confidencetells you when the model is guessing from genre cues. - Not a replacement for playing. Same transience as any preset hunt — you still need to dial in the room, the pick, the doubles, the attitude?
- “Tone is in the fingers”
I’m not claiming Mutt Lange in a box. But these experiments have yielded a repeatable pipeline that buys back the time I’d rather spend actually playing. In an age of shallow AI-music and algorithmic slop, it’s deeply satisfying to light up the room with the tone that shredded arenas in the glory days.
On to more jamming…
Subscribe to posts
New posts on data, AI, Audio and other oddities - straight to your inbox.
Subscribe



One comment on “Dialing In the Ghost in the Machine: LLMs for guitar tones”