Music generation with Recurrent Neural Nets has been of great interest to me with projects like Magenta displaying amazing feats of ML-driven creativity. AI is increasingly being used to augment human creativity and this trend will lay to rest creativity blocks like in the future. As someone who is usually stuck in a musical rut, this is great for spurring creativity.
With a few covid-induced reconnects with old friends (some of whom are professional musicians) and some inspired late night midi programming on Ableton, I decided to modify some scripts / tutorials that have been lying around on my computer to blend deep learning and compose music around it as I research on the most optimal ways to integrate Deep Learning into original guitar music compositions.
There’s plenty of excellent blogs and code on the web on LSTMs including this one and this one on generating music using Keras. LSTMs have plenty of boiler plate code on github that demonstrate LSTM and GRUs for creating music. For this project, I was going for recording a guitar solo based on artists I like and to set up a template for future experimentation for research purposes. A few mashed up solos of 80s guitar solos served as the source data but the source data could have been pretty much anything in the midi format and it helps to know how to manipulate these files in the DAW, which in my case was Ableton. Most examples on the web have piano midi files that generate music in isolation. However, I wanted to combine the generated music with minimal accompaniment so as to make it “real”.
With the key of the track being trained on being in F Minor , I also needed to make sure i have some accompaniment in the key of FMinor for which I recorded a canned guitar part with some useful drum programming thanks to EZDrummer.
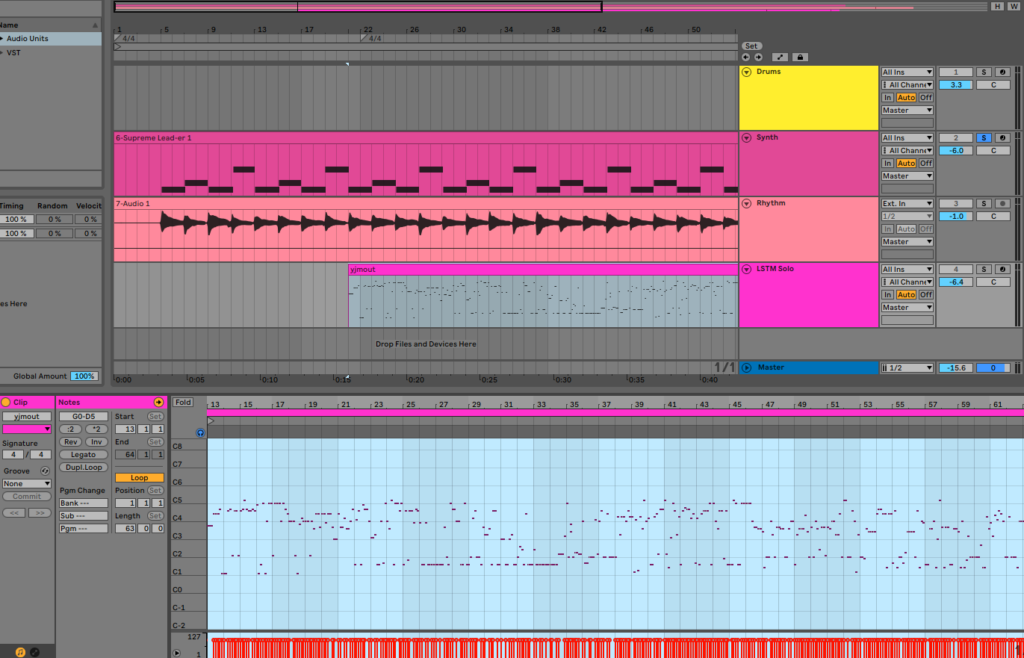
Note: this was for research purposes only and for further research into composing pieces that actually make sense based on the key being fed into the model.
Music21 is invaluable for manipulating midi via code. Its utility is that is lets us manipulate starts, durations and pitch. I used Ableton to use the midi notes generated to plug in an instrument along with programmed drums and rhythm guitars.
Step 1:
Find the midi file(s) you want to base your ML solo on. In this case, Im going for generating a guitar solo to layer over a backing track. This could be pretty much anything as long as its midi that can be processed by Music21.
Step 2:
Preprocessing the midi file(s): The original midi file had guitars over drums, bass and keyboards. So, the goal was to extract the list of notes first to save them, the instrument.partitionByInstrument() function, separates the stream into different parts according to the instrument. If we have multiple files we can loop over the different files to partition it by individual instrument. This returns a list of notes and chords in the file.
from tqdm import tqdm
songs = glob(' /ml/vish/audio_lstm/YJM.mid') # this could be any midi file to be trained
notes = []
for file in tqdm(songs):
midi = converter.parse(file) # convert all supported data formates to music21 objects
notes_parser = None
try:
# partition parts for each unique instrument
parts = instrument.partitionByInstrument(midi)
except:
print("No uniques")
if parts:
notes_parser = parts.parts[0].recurse()
else:
notes_parser = midi.flat.notes # flatten notes to get all the notes in the stream
print("parts == None")
for element in notes_parser:
if isinstance(element, note.Note):# check if elements are in the note class
notes.append(str(element.pitch)) # Returns Pitch objects found as a Python List
elif(isinstance(element, chord.Chord)):
notes.append('.'.join(str(n) for n in element.normalOrder))
print("notes:", notes)Step 3:
Creating the model inputs: Convert the items in the notes list to an integer so they can serve as model inputs. We create arrays for the network input and output to train the model. We have 5741 notes in our input data and have defined a sequence length of 50 notes. The input sequence will be 50 notes and the output array will store the 51st note for every input sequence that we enter. Then we reshape and normalize the input vector sequence. We also one hot encoder on the integers so that we have the number of columns equal to the number of categories to get a network output shape of (5691, 92). I’ve commented out some of the output so the results are easier to follow.
pitch_names = sorted(set(item for item in notes)) # ['0', '0.3.7', '0.4.7', '0.5', '1', '1.4.7', '1.5.8', '1.6', 10', '10.1.5',..]
note_to_int = dict((note, number) for number, note in enumerate(pitch_names)) #{'0': 0,'0.3.7': 1, '0.4.7': 2,'0.5': 3, '1': 4,'1.4.7': 5,..]
sequence_length = 50
len(pitch_names) # 92
range(0, len(notes) - sequence_length, 1) #range(0, 5691)
# Deifne input and output sequence
network_input = []
network_output = []
for i in range(0, len(notes) - sequence_length, 1):
sequence_in = notes[i: i + sequence_length]
sequence_out = notes[i + sequence_length]
network_input.append([note_to_int[char] for char in sequence_in])
network_output.append(note_to_int[sequence_out])
print("network_input shape (list):", (len(network_input), len(network_input[0]))) #network_input shape (list): (5691, 50)
print("network_output:", len(network_output)) #network_output: 5691
patterns = len(network_input)
print("patterns , sequence_length",patterns, sequence_length) #patterns , sequence_length 5691 50
network_input = np.reshape(network_input, (patterns , sequence_length, 1)) # reshape to array of (5691, 50, 1)
print("network input",network_input.shape) #network input (5691, 50, 1)
n_vocab = len(set(notes))
print('unique notes length:', n_vocab) #unique notes length: 92
network_input = network_input / float(n_vocab)
# one hot encode the output vectors to_categorical(y, num_classes=None)
network_output = to_categorical(network_output)
network_output.shape #(5691, 92)Step 4:
Model: We invoke Keras to build out the model architecture using LSTM. Each input note is used to predict the next note. Code below uses standard model architecture from tutorials without too many tweaks. Plenty of tutorials online that explain the model way better than I can such as this: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Training on the midi input can be expensive and time consuming so I suggest setting a high epoch number with calls backs defined based on the metrics to monitor, In this case, I used loss and also created checkpoints for recovery and save the model as ‘weights.musicout.hdf5’. Also note , I trained this on community edition Databricks for convenience.
def create_model():
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, LSTM, Dropout, Flatten
model = Sequential()
model.add(LSTM(128, input_shape=network_input.shape[1:], return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(128, return_sequences=True))
model.add(Flatten())
model.add(Dense(256))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=["accuracy"])
model.summary()
return model
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
model = create_model()
save_early_callback = EarlyStopping(monitor='loss', min_delta=0,
patience=3, verbose=1,
restore_best_weights=True)
epochs = 5000
filepath = 'weights.musicout.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=0, save_best_only=True)
model.fit(network_input, network_output, epochs=epochs, batch_size=32, callbacks=[checkpoint,save_early_callback])
Step 5:
Predict: Once we have the model trained, we can start generating nodes based on the trained model weights along with feeding the model a sequence of notes. We can pick a random integer and a random sequence from the input sequence as a starting point. In my case, it involved calling the model.predict function for a 1000 notes that can be converted to a midi file. The results might vary at this stage, for some reason I saw some degradation after 700 notes so some tuning required here.
start = np.random.randint(0, len(network_input)-1) # randomly pick an integer from input sequence as starting point
print("start:", start)
int_to_note = dict((number) for number in enumerate(pitch_names))
pattern = network_input[start]
prediction_output = [] # store the generated notes
print("pattern.shape:", pattern.shape)
pattern[:10] # check shape
# generating 1000 notes
for note_index in range(1000):
prediction_input = np.reshape(pattern, (1, len(pattern), 1))
prediction_input = prediction_input / float(n_vocab)
prediction = model.predict(prediction_input, verbose=0) # call the model predict function to predict a vector of probabilities
predict_index = np.argmax(prediction) # Argmax is finding out the index of the array that results in the largest predict value
#print("Prediction in progress..", predict_index, prediction)
result = int_to_note[predict_index]
prediction_output.append(result)
pattern = np.append(pattern, predict_index)
# Next input to the model
pattern = pattern[1:1+len(pattern)]
print('Notes generated by model...')
prediction_output[:25] # Out[30]: ['G#5', 'G#5', 'G#5', 'G5', 'G#5', 'G#5', 'G#5',...Step 6:
Convert to Music21: Now that we have our prediction_output numpy array with the predicted notes, it’s time to convert it back into a format that Music21 can recognize with the objective of converting that back to a midi file.
offset = 0
output_notes = []
# create note and chord objects based on the values generated by the model
# convert to Note objects for music21
for pattern in prediction_output:
if ('.' in pattern) or pattern.isdigit(): # pattern
notes_in_chord = pattern.split('.')
notes = []
for current_note in notes_in_chord:
new_note = note.Note(int(current_note))
new_note.storedInstrument = instrument.Piano()
notes.append(new_note)
new_chord = chord.Chord(notes)
new_chord.offset = offset
output_notes.append(new_chord)
else: # pattern
new_note = note.Note(pattern)
new_note.offset = offset
new_note.storedInstrument = instrument.Piano()
output_notes.append(new_note)
# increase offset each iteration so that notes do not stack
offset += 0.5
#Convert to midi
midi_output = music21.stream.Stream(output_notes)
print('Saving Output file as midi....')
midi_output.write('midi', fp=' /ml/vish/audio_lstm/yjmout.midi')Step 7:
Once we have the midi file with the generated notes, the next step was to load the midi track into Ableton. The next steps were standard recording processes one would follow to record a track in the DAW.
a) Compose and Record the Rhythm guitars, drums and Keyboards.
Instruments/software I used:
- Alesis V49 for synths
- Ibanez RG3550 guitar
- EZDrummer2 programmed drums
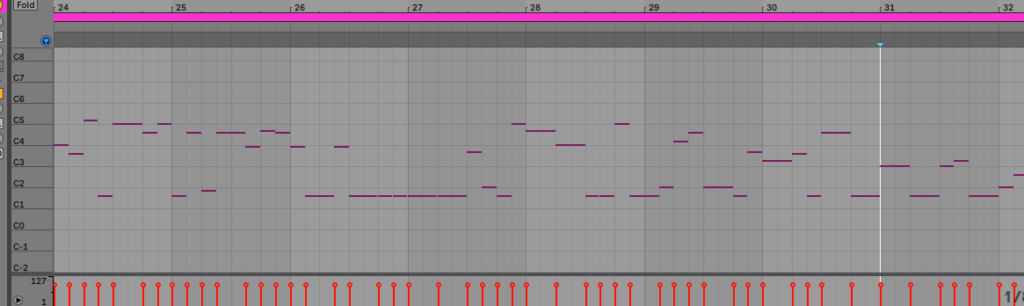
b) Insert the midi track into the DAW and quantize and sequence accordingly. This can take significant time depending on the precision wanted. In my case, this was just a quick fun project not really destined for the charts so a quick rough mix and master sufficed.
The track is on soundcloud here. The solo kicks in around the 16 second mark. Note I did have to adjust the pitch to C to blend in with the rhythm track though it was originally trained on a track in F minor
There are other ways of dealing with more sophisticated training like using different activation functions or by normalizing inputs. GRUs are another way to get past this problem and I plant iterate on more complex pieces blending deep learning with my compositions. This paper gives a great primer on the difference between LSTMs and GRUs: https://www.scihive.org/paper/1412.355