
Working with my teams trying to build out a robust feature store these days, it’s becoming even more imperative to ensure feature Engineering data quality. The models that gain efficiency out of a performant feature store are only as good as the underlying data.
Tensorflow Data Validation (TFDV) is a python package from the TF Extended ecosystem. The package has been around for a while but now has evolved to a point of being extremely useful for machine learning pipelines as part of feature engineering and determining data drift scenarios. Its main functionality is to compute descriptive statistics, infer schema,and detect data anomalies. It’s well integrated with the Google Cloud Platform and Apache Beam. The core API uses Apache Beam transforms to compute statistics over input data.
I end up using it in cases where I need quick checks on data to validate and identify drift scenarios before starting expensive training workflows. This post is a summary of some of my notes on the usage of the package. Code is here.
Data Load
TFDV accepts CSV, Dataframes or TFRecords as input.
The csv integration and the built-in visualization function makes it relatively easy to use within Jupyter notebooks. The library takes input feature data and then analyzes them by feature to visualize them. This makes it easy to get a quick understanding of the distribution of values, helps identifying anomalies and identifying training/test/validate skew. Also a great way to discover bias in the data since you can infer aggregates of values that skewed towards certain features.
As evident, with trivial amount of code you can spot issues immediately – missing columns, inconsistent distribution and data drift scenarios where newer dataset could have different statistics compared to earlier trained data.
I used a dataset from Kaggle to quickly illustrate the concept:
import tensorflow_data_validation as tfdv
train = tfdv.generate_statistics_from_csv(data_location='Data/Musical_instruments_reviews.csv', delimiter=',')
# Infer schema
schema = tfdv.infer_schema(TRAIN)
tfdv.display_schema(schema)This generates a data structure that stores summary statistics for each feature.
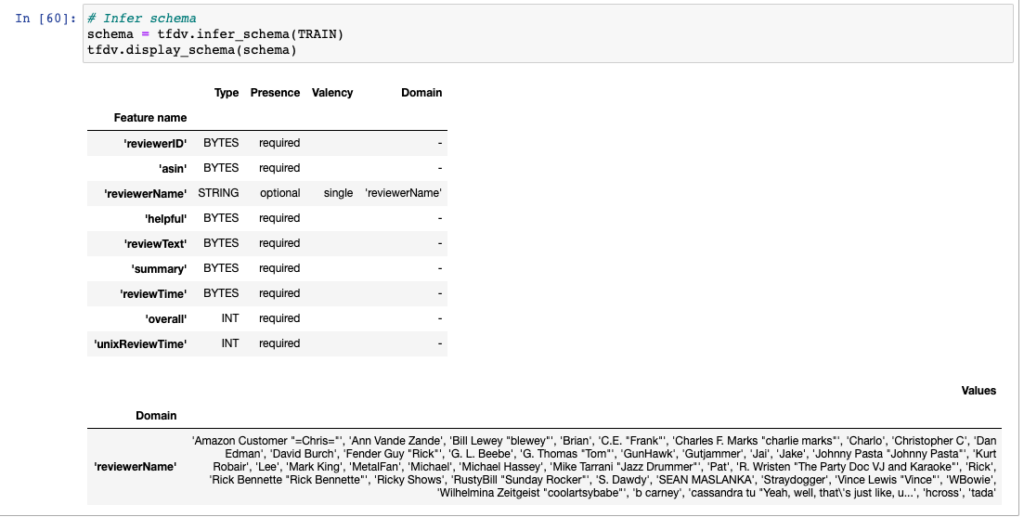
Schema Inference
The schema properties describe every feature present in the 10261 reviews. Example:
- their type (STRING)
- Uniqueness of features – for example 1429 unique reviewer IDs.
- the expected domains of features.
- the min/max of the number of values for a feature in each example. For example: If A2EZWZ8MBEDOLN is a reviewerid and has 36 occurrences
top_values {
value: "A2EZWZ8MBEDOLN"
frequency: 36.0
}
datasets {
num_examples: 10261
features {
type: STRING
string_stats {
common_stats {
num_non_missing: 10261
min_num_values: 1
max_num_values: 1
avg_num_values: 1.0
num_values_histogram {
buckets {
low_value: 1.0
high_value: 1.0
sample_count: 1026.1
}
buckets {
low_value: 1.0
high_value: 1.0
sample_count: 1026.1
}
Schema inference is usually tedious but becomes a breeze with TFDV. This schema is stored as a protocol buffer.
schema = tfdv.infer_schema(train)
tfdv.display_schema(schema)The schema also generates definitions like “Valency” and “Presence”. I could not find too much detail in the documentation but I found this useful paper that describes it well.
- Presence: The expected presence of each feature, in terms of a minimum count and fraction of examples that must contain the feature.
- Valency: The expected valency of the feature in each example, i.e., minimum and maximum number of values.
TFDV has inferred the revewerName as STRING and the universe of values around them termed as Domain. Note – TFDV can also encode your fields as BYTES. Im not seeing any function call in the API to update the column type as-is but you could easily update it externally if you want to explicitly specify a string. From the documentation, its explicitly advised to review the inferred schema and refine it per the requirement so as to embellish this auto-inference with our domain knowledge based on the data. You could also update the Feature based on the Data Type to BYTES, INT, FLOAT or STRUCT.
# Convert to BYTES
tfdv.get_feature(schema, 'helpful’).type=1
Once loaded, you can generate the statistics from the csv file.
For a comparison and to simulate a dataset validation scenario, I cut down the Musical_instruments_reviews.csv to 100 rows to compare with the original and also added an extra feature called ‘Internal’ with the values A, B,C randomly interspersed for every row.
Visualize Statistics
After this you can pass in the ‘visualize_statistics’ call to first visualize the two datasets based on the schema of the first dataset (TRAIN in the code). Even though this is limited to two datasets, this is a powerful way to identify issues immediately. For example – it can right off the bat identify “missing features” such as over 99.6% values in the feature. “reviewerName” as well as split the visualization into numerical and categorical features based on its inference of the data type.
# Load test data to compare
TEST = tfdv.generate_statistics_from_csv(data_location='Data/Musical_instruments_reviews_100.csv', delimiter=',')
# Visualize both datasets
tfdv.visualize_statistics(lhs_statistics=TRAIN, rhs_statistics=TEST, rhs_name="TEST_DATASET",lhs_name="TRAIN_DATASET")
A particularly nice option is the ability to choose a log scale for validating categorical features. The ‘Percentages’ option can show quartile percentages.
Anomalies
Anomalies can be detected using the display_anomalies call. The long and short descriptions allow easy visual inspection of the issues in the data. However, for large scale validation this may not be enough and you will need to use tooling that handle a stream of defects being presented.
# Display anomalies
anomalies = tfdv.validate_statistics(statistics=TEST, schema=schema)
tfdv.display_anomalies(anomalies)
The various kinds of anomalies that can be detected and their invocation are described here. Some especially useful ones are:
- SCHEMA_MISSING_COLUMN
- SCHEMA_NEW_COLUMN
- SCHEMA_TRAINING_SERVING_SKEW
- COMPARATOR_CONTROL_DATA_MISSING
- COMPARATOR_TREATMENT_DATA_MISSING
- DATASET_HIGH_NUM_EXAMPLES
- UNKNOWN_TYPE

Schema Updates
Another useful feature here is the ability to update the schema and values to make corrections. For example, in order to insert a particular value
# Insert Values
names = tfdv.get_domain(schema, 'reviewerName').value
names.insert(6, "Vish") #will insert "Vish" as the 6th value of the reviewerName featureYou can also adjust the minimum number of values that must be preset in the domain and choose to drop it if is below a certain threshold.
# Relax the minimum fraction of values that must come from the domain for feature reviewerName
name = tfdv.get_feature(schema, 'reviewerName')
name.distribution_constraints.min_domain_mass = 0.9Environments
The ability to split data into ‘Environments’ helps indicate the features that are not necessary in certain environments. For example,if we want the ‘internal’ column to be in the TEST data but not the TRAIN data. Features in schema can be associated with a set of environments using:
- default_environment
- in_environment
- not_in_environment
# All features are by default in both TRAINING and SERVING environments.
schema2.default_environment.append('TESTING')
# Specify that 'Internal' feature is not in SERVING environment.
tfdv.get_feature(schema2, 'Internal').not_in_environment.append('TESTING')
tfdv.validate_statistics(TEST, schema2, environment='TESTING')
#serving_anomalies_with_envSample anomaly output:
string_domain {
name: "Internal"
value: "A"
value: "B"
value: "C"
}
default_environment: "TESTING"
}
anomaly_info {
key: "Internal"
value {
description: "New column Internal found in data but not in the environment TESTING in the schema."
severity: ERROR
short_description: "Column missing in environment"
reason {
type: SCHEMA_NEW_COLUMN
short_description: "Column missing in environment"
description: "New column Internal found in data but not in the environment TESTING in the schema."
}
path {
step: "Internal"
}
}
}
anomaly_name_format: SERIALIZED_PATHSkews & Drifts
The ability to detect data skews and drifts is invaluable. However, the drift here does not indicate a divergence from the mean but refers to the “L-infinity” norm of the difference between the summary statistics of the two datasets. We can specify a threshold which if exceeded for the given feature flags the drift.
Lets say we have two vectors [2,3,4] and [-4,-7,8] , the L-infinity norm is the maximum absolute value of the difference between the two vectors so in this case the absolute maximum of [6,10,-4] which is 1.
#Skew comparison
tfdv.get_feature(schema,
'helpful').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(statistics=TRAIN,
schema=schema,
serving_statistics=TEST)
skew_anomaliesSample Output:
anomaly_info {
key: "helpful"
value {
description: "The Linfty distance between training and serving is 0.187686 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: [0, 0]"
severity: ERROR
short_description: "High Linfty distance between training and serving"
reason {
type: COMPARATOR_L_INFTY_HIGH
short_description: "High Linfty distance between training and serving"
description: "The Linfty distance between training and serving is 0.187686 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: [0, 0]"
}
path {
step: "helpful"
}
}
}
anomaly_name_format: SERIALIZED_PATHThe drift comparator is useful in cases where you could have the same data being loaded in a frequent basis and you need to watch for anomalies to reengineer features. The validate_statistics call combined with the drift_comparator threshold can be used to monitor for any changes that you need to action on.
#Drift comparator
tfdv.get_feature(schema,'helpful').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(statistics=TRAIN,schema=schema,previous_statistics=TRAIN)
drift_anomaliesAnomaly_info {
key: "reviewerName"
value {
description: "The feature was present in fewer examples than expected."
severity: ERROR
short_description: "Column dropped"
reason {
type: FEATURE_TYPE_LOW_FRACTION_PRESENT
short_description: "Column dropped"
description: "The feature was present in fewer examples than expected."
}
path {
step: "reviewerName"
}
}
}
You can easily save the updated schema in the format you want for further processing.
Overall, this has been useful to me to use for mainly models within the TensorFlow ecosystem and the documentation indicates that using components like StatisticsGen with TFX makes this a breeze to use in pipelines with out-of-the box integration on a platform like GCP.
The use case for avoiding time-consuming preprocessing/training steps by using TFDV to identify anomalies for feature drift and inference decay is a no-brainer however defect handling is up to the developer to incorporate. It’s important to also consider that ones domain knowledge on the data plays a huge role in these scenarios for optimizing data according to your needs so an auto-fix on all data anomalies may not really work in cases where a careful review is unavoidable.
This can also be extended for overall general data quality by applying to any validation cases where you are constantly getting updated data for the features. The application of TFDV could even be post-training for any data input/output scenario to ensure that values are as expected.
Official documentation is here.
Subscribe to posts
New posts on data, AI, Audio and other oddities - straight to your inbox.
Subscribe



One comment on “TFDV for Data validation”