Hugging Face is the go-to resource open source natural language processing these days. The Hugging Face hubs are an amazing collection of models, datasets and metrics to get NLP workflows going. Its relatively easy to incorporate this into a mlflow paradigm if using mlflow for your model management lifecycle. mlflow makes it trivial to track model lifecycle, including experimentation, reproducibility, and deployment. mlflow’s open format makes it my go-to framework for tracking models in an array of personal projects and It also has an impressive enterprise implementation that my teams at work enable for large enterprise use cases. For smaller projects, its great to use mlflow locally for any projects that requires model management as this example illustrates.
The beauty of Hugging Face (HF) is the ability to use their pipelines to to use models for inference. The models are products of massive training workflows performed by big tech and available to ordinary users who can use them for inference. The HF pipelines offer a simple API dedicated to performing inference in these models thus sparing the ordinary the user the complexity and compute / storage requirements for running such large models.
The goal was to put some sort of tracking around all my experiments with the Hugging Face Summarizer that I’ve been using to summarize text and then use the mlflow Serving via REST as well as running predictions on the inferred model by passing in a text file. Code repository is here with snippets below.
Running the Text Summarizer and calling it via curl
Text summarization consists of Extractive and Abstractive types where Extractive selects sentence that has the most valuable context while Abstractive is trained to create summaries.
Considering I was running on a CPU, I picked a small model like the T5-small model trained on Wikihow All data set that has been trained to write summaries. The boiler plate code on the HuggingFace website gives you all you need to get started. Note that this models input length is set to 512 tokens max which may not be optimum for usecases with larger text.
a) First step is to define a wrapper around the model code so it can be called easily later on by subclassing it with the mlflow.pyfunc.PythonModel to use custom logic and artifacts.
class Summarizer(mlflow.pyfunc.PythonModel):
'''
Any MLflow Python model is expected to be loadable as a python_function model.
'''
def __init__(self):
from transformers import pipeline, AutoTokenizer, AutoModelWithLMHead
self.tokenizer = AutoTokenizer.from_pretrained(
"deep-learning-analytics/wikihow-t5-small")
self.summarize = AutoModelWithLMHead.from_pretrained(
"deep-learning-analytics/wikihow-t5-small")
def summarize_article(self, row):
tokenized_text = self.tokenizer.encode(row[0], return_tensors="pt")
# T5-small model trained on Wikihow All data set.
# model was trained for 3 epochs using a batch size of 16 and learning rate of 3e-4.
# Max_input_lngth is set as 512 and max_output_length is 150.
s = self.summarize.generate(
tokenized_text,
max_length=150,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True)
s = self.tokenizer.decode(s[0], skip_special_tokens=True)
return [s]
def predict(self, context, model_input):
model_input[['name']] = model_input.apply(
self.summarize_article)
return model_inputb) We define the tokenizer to prepare the inputs of the model and the model using the HuggingFace specifications. This is a smaller model trained on Wikihow All data set. From the documentation – the model was trained for 3 epochs using a batch size of 16 and learning rate of 3e-4. Max_input_length is set as 512 and max_output_length is 150.
c) Then define the model specifications of the T5-small model by calling the summarize_article function with the tokenized text that will called it for every row in the dataframe input and eventually return the prediction.
d) The prediction function calls the summarize_article providing the model input and calling the summarizer and returns the prediction. This is also where we can plug in mlflow to infer the predictions.
The input and output schema are defined in the ModelSignature class as follows :
# Input and Output formats
input = json.dumps([{'name': 'text', 'type': 'string'}])
output = json.dumps([{'name': 'text', 'type': 'string'}])
# Load model from spec
signature = ModelSignature.from_dict({'inputs': input, 'outputs': output}) input = json.dumps([{'name': 'text', 'type': 'string'}])
output = json.dumps([{'name':'text', 'type':'string'}])
e) We can set mlflow operations by setting the tracking URI which was “” in this case since its running locally. Its trivial in a platform like Azure to spin up a databricks workspace and get a tracking server spun up automatically so you can persist all artifacts at cloud scale.
Start tracking the runs by wrapping the mlflow.start_run invocation. The key here is to call the model for inference using the mlflow.pyfunc function to make the python code load into mlflow. In this case , the dependencies of the model are all stored directly with the model. Plenty of parameters here that can be tweaked described here.
# Start tracking
with mlflow.start_run(run_name="hf_summarizer") as run:
print(run.info.run_id)
runner = run.info.run_id
print("mlflow models serve -m runs:/" +
run.info.run_id + "/model --no-conda")
mlflow.pyfunc.log_model('model', loader_module=None, data_path=None, code_path=None,
conda_env=None, python_model=Summarizer(),
artifacts=None, registered_model_name=None, signature=signature,
input_example=None, await_registration_for=0)
f) Check the runs via mlflow UI either using the “mlflow ui” command or just invoke the commandmlflow models serve -m runs:/<run_id>
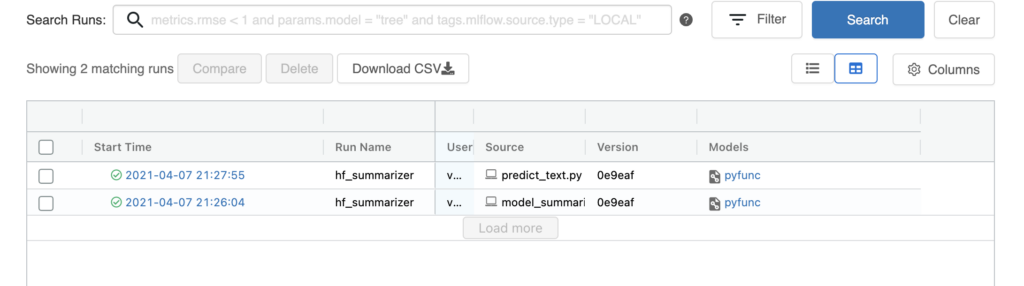
g) Thats it – Call the curl command using sample text below:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["text"],"data":[["Howard Phillips Lovecraft August 20, 1890 – March 15, 1937) was an American writer of weird and horror fiction, who is known for his creation of what became the Cthulhu Mythos.Born in Providence, Rhode Island, Lovecraft spent most of his life in New England. He was born into affluence, but his familys wealth dissipated soon after the death of his grandfather. In 1913, he wrote a critical letter to a pulp magazine that ultimately led to his involvement in pulp fiction.H.P.Lovecraft wrote his best books in Masachusettes."]]}' http://127.0.0.1:5000/invocationsOutput:
"name": "Know that Howard Phillips Lovecraft (H.P.Lovecraft was born in New England."}]%Running the Text Summarizer and calling it via a text file
For larger text, its more convenient reading the text from a file, formatting it and running the summarizer on it. The predict_text.py does exactly that.
a) Clean up the text in article.txt and load the text into a dictionary.
b) Load the model using pyfunc.load_model and then run the model.predict on the dictionary.
# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(logged_model)
# Predict on a Pandas DataFrame.
summary = loaded_model.predict(pd.DataFrame(dict1, index=[0]))
print(summary['name'][0])Code here
In summary, this makes for a useful way to track models and outcomes from readily available transformer pipelines to pick the best ones for the task.
Subscribe to posts
New posts on data, AI, Audio and other oddities - straight to your inbox.
Subscribe