DQ Framework
Data quality is one of the biggest asks from consumers of the data in large…

Data quality is one of the biggest asks from consumers of the data in large…

I discovered Tenacity while encountering a bunch of gobbledygook shell and python scripts crunched together…

by Sebastian Raschka & Vahid Mirjalili I primarily wanted to read this book due to…

The usual Synchronous versus Asynchronous versus Concurrent versus Parallel is a topic in technical interviews…

I’ve enjoyed the different eras of Genesis regardless of the Peter Gabriel-era prog-rock or the…
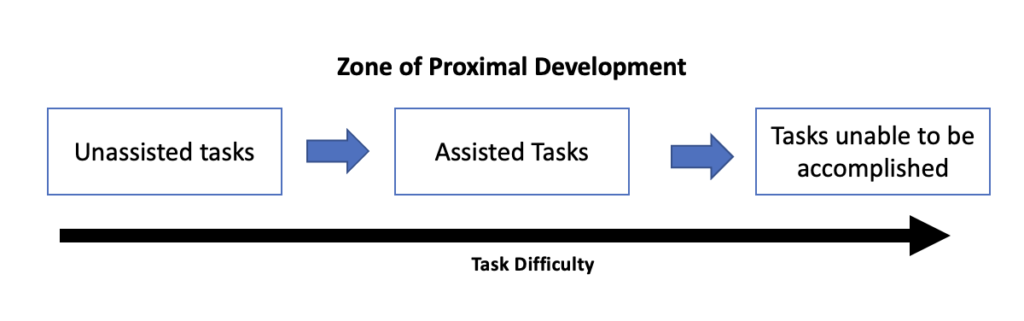
Essentially ZPD is the place where once cannot progress in their learning without the interaction…
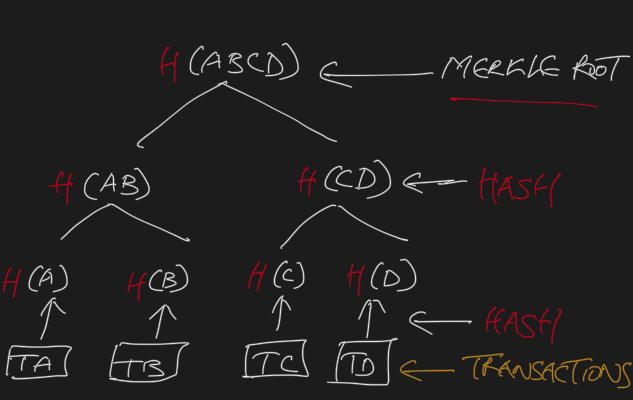
A hash-based comparison approach like Merkle tree would help quickly compare two copies of a…
First Principles is a collaboration between Bass Player/ Composer Arjun Raghuraman and Guitarist/Composer Vishwanath Subramanian.

Prisoners of Geography: Ten Maps That Explain Everything About the World by Tim Marshall is…

Hugging Face is the go-to resource open source natural language processing these days. The Hugging…