The Bob Spitz biography stares at me all day as I spend most of my waking hours at my home office desk taunting me to finish it one of these days. Probably subliminally influenced me to write a quick app to generate lyrics using a Recurrent Neural Net. The Databricks community edition or Google collab makes it a breeze to train these models at a zero or reasonable price point using GPUs.
All the buzz around GPT-3 and my interest in Responsible AI is helping inspire some late night coding sessions blown away by the accuracy of some of these pretrained language models. Also wanted to play around with Streamlit which saves me from tinkering around with javascript frameworks and what not while trying to deploy an app. The lack of a WSGI option limits some deployment options but I found it relatively easy to containerize and deploy on Azure.
The official TensorFlow tutorial is great for boilerplate which in turn is based on this magnum opus. The tutorial is pretty straight forward and google collab is great for training on GPUs.
Plenty of libraries available to scrape data – this one comes to mind. The model is character-based and predicts the next character in the sequence given a sequence. I tweaked around training this on small batches of text and finally settled on around 150 characters to start seeing some coherent structures. My source data scould do better, it stops after Help I believe. On my todo list is to embellish it with full discography so as to make the model better.
The model summary is as defined below:
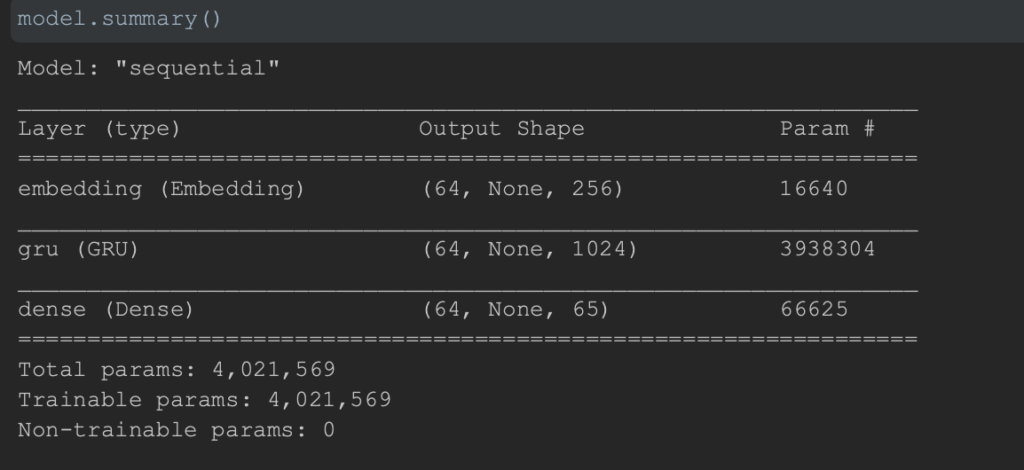
Didn’t really have to tweak the sequential model too much to start seeing some decent output. The 3 layers were enough along with a Gated Recurrent Unit ( GRU). The GRU seemed to give me a better output than LSTM so I let it be…
As per the documentation, for each character the embedding is inputted into the GRU which is then run with one timestep. The dense layer generates the logits predicting the log-likelihood of the next character.
For each character the model looks up the embedding, runs the GRU one timestep with the embedding as input, and applies the dense layer to generate logits predicting the log-likelihood of the next character.
The standard tf.keras.losses.sparse_categorical_crossentropy loss function is my usual go-to in this case because the classes are all mutually exclusive. Couldn’t get past 50 epochs on my mac book pro without the IDE hanging so had to shift to a Databricks instance which got the job done with no sweat on a 28.0 GB Memory, 8 Core machine.
All things must pass and 30 minutes later, we had a trained model thanks to an early stopping callback monitoring loss.
The coolest part of the RNN is the text generating function from the documentation that you can configure the number of characters to generate. It uses the start string and the RNN state to get the next character. The next predicted character is based on the categorical distribution which provides the index of the highest distributed category as the next input into the model. The state of the model is retained per input and modified states of the model are fed back into the model to help it learn. This is the magical mystery of the model. Plenty of more training to do as I wait for the Peter Jackson release.
Link to app: https://stream-web-app.azurewebsites.net/
Github: https://github.com/vishwanath79/let_it_read
Subscribe to posts
New posts on data, AI, Audio and other oddities - straight to your inbox.
Subscribe